快速适应测试时间分布变化
发布于:2020-12-19 18:38:42
想象一下,您正在构建用于手写笔迹的下一代机器学习模型。根据产品的先前迭代,您已经确定了此部署的主要挑战:部署后,新的最终用户通常具有不同且看不见的笔迹样式,从而导致发行转移。解决此难题的一种方法是学习一种自适应模型,该模型可以随着时间的推移专门化并适应每个用户的笔迹样式。该解决方案看似很有希望,但必须与对易用性的关注进行权衡:要求用户向模型提供反馈可能很麻烦并且阻碍了采用。而是可以学习一个无需标签即可适应新用户的模型吗?
在许多情况下,包括此示例,答案是“是”。考虑下图中放大显示的歧义示例。此字符是带循环的“ 2”还是双层“ a”?对于关注训练数据偏差的非自适应模型,合理的预测将为“ 2”。但是,即使没有标签,我们也可以从用户的其他示例中提取有用的信息:例如,一个自适应模型可以观察到该用户写了“ 2”且没有循环,并得出结论认为该字符更有可能是“ a”。 ”。
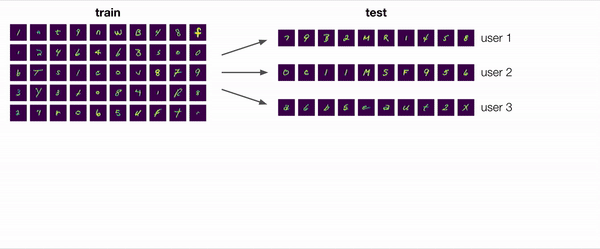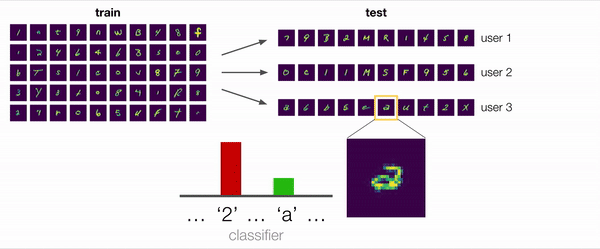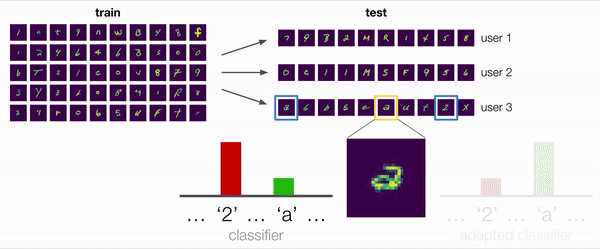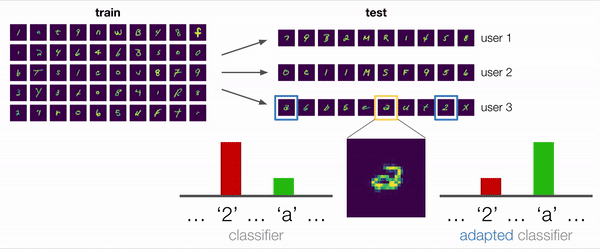
处理因将模型部署到新用户而产生的分布变化,是无标签适应的重要激励示例。但是,这远非唯一的例子。在瞬息万变的世界中,自动驾驶汽车需要适应新的天气条件和位置,图像分类器需要适应具有不同内在特性的新相机,推荐系统则需要适应用户不断变化的偏好。通过从测试示例的分布中推断出信息,人类已经证明了无需标签就能适应的能力。我们是否可以开发允许机器学习模型执行相同操作的方法?
这个问题已引起研究人员的越来越多的关注,最近的许多工作提出了无标记的测试时间适应方法。在这篇文章中,我将调查这些作品以及其他处理分配偏移的杰出框架。有了这个大背景下,我会再讨论我们最近的工作(见文章在这里和代码在这里),其中我们提出了一个问题,制定我们长期适应性风险最小化,或ARM。
进入分配转移
机器学习中的绝大多数工作都遵循经验风险最小化(ERM)的规范框架。ERM方法假定没有分布偏移,因此测试分布与训练分布完全匹配。该假设简化了强大的机器学习方法的开发和分析,但是,如上所述,在现实世界的应用程序中通常会违反这一假设。为了超越ERM并学习面对分销变化而泛化的模型,我们必须引入其他假设。但是,我们必须谨慎选择这些假设,以使它们仍然是现实的并且广泛适用。
我们如何保持现实性和适用性?答案之一是根据机器学习系统在现实世界中面临的条件对假设进行建模。例如,在ERM设置中,一次在每个测试点上评估模型,但在现实世界中,这些测试点通常可以顺序或批量使用。例如,对于笔迹转录,我们可以想象从新用户那里收集整个句子和段落。如果存在分布偏移,则即使没有标签,也可以观察多个测试点来推断测试分布或以其他方式使模型适应此新分布。
使用此假设的许多最新方法可以归类为测试时间适应性,包括批处理归一化,标签偏移估计,旋转预测,熵最小化等。通常,这些方法会产生强大的归纳偏置,从而可以进行有用的调整。例如,旋转预测与许多图像分类任务完全吻合。但是这些方法通常要么建议启发式训练程序,要么根本不考虑训练程序,而是依靠预先训练的模型。1个 这就引出了一个问题:可以通过改进训练来进一步提高测试时间的适应性,从而使模型可以更好地利用适应性程序吗?
我们可以通过研究其他重要的框架来处理分配变动,尤其是这些框架所做的假设,来深入了解这个问题。在实际应用中,训练数据通常不仅仅由输入标签对组成;而是由输入标签对组成。相反,还有与每个示例关联的其他元数据,例如时间和位置,或手写示例中的特定用户。这些元数据可用于将训练数据分组,2在许多框架中,一个普遍的假设是测试时间分布的变化代表新的组分布或新的组。这个假设仍然允许各种各样的实际分布变化,并推动了许多实际方法的发展。
例如,领域适应方法通常假定访问两个训练组:源数据和目标数据,后者是从测试分布中提取的。因此,这些方法例如通过重要性 加权或学习不变 表示来增强训练以集中于目标分布。为方法组 分布式地稳健 优化和域名 推广不要直接假设访问测试分布中的数据,而是使用从多个培训组中提取的数据来学习一个模型,该模型可以在测试时推广到新的组(或新的组分布)。因此,这些先前的工作主要集中在训练过程上,并且通常在测试时不适应(尽管名称为“领域适应”)。
结合训练和测试假设
先前的分配变动框架假设采用培训小组或测试批次,但是我们不知道有任何使用这两种假设的先前工作。在我们的工作中,我们证明正是这种结合使我们能够通过模拟训练时的偏移和适应过程来学习适应测试时间分布的偏移。通过这种方式,我们的框架可以理解为元学习框架,并且我们将感兴趣的读者推荐给这篇博客,以获取有关元学习的详细概述。
自适应风险最小化
我们的工作提出了自适应风险最小化(ARM),这是一个问题设置和目标,在培训时同时使用两组,在测试时进行批量处理。通过元学习的角度,这种综合为如何训练测试时间适应性问题提供了一个通用的原则性答案。特别地,我们使用训练组启用的模拟分布偏移对模型进行元训练,以使其表现出强大的自适应能力每个班次的表现。因此,该模型直接学习如何最好地利用适应过程,然后在测试时以完全相同的方式执行该过程。如果我们能够确定可能发生哪些测试分布变化,例如查看新的最终用户的数据,那么我们可以更好地构建模拟的训练变化,例如仅从一个特定的训练用户那里采样数据。

上图显示了用于优化ARM目标的培训过程。从训练数据中,我们对模拟不同群体分布变化的不同批次进行采样。这样,适应模型就有机会使用未标记的示例来适应模型参数。这允许我们通过直接在模型和适应模型上执行梯度更新来对模型进行元训练,以适应后的性能。
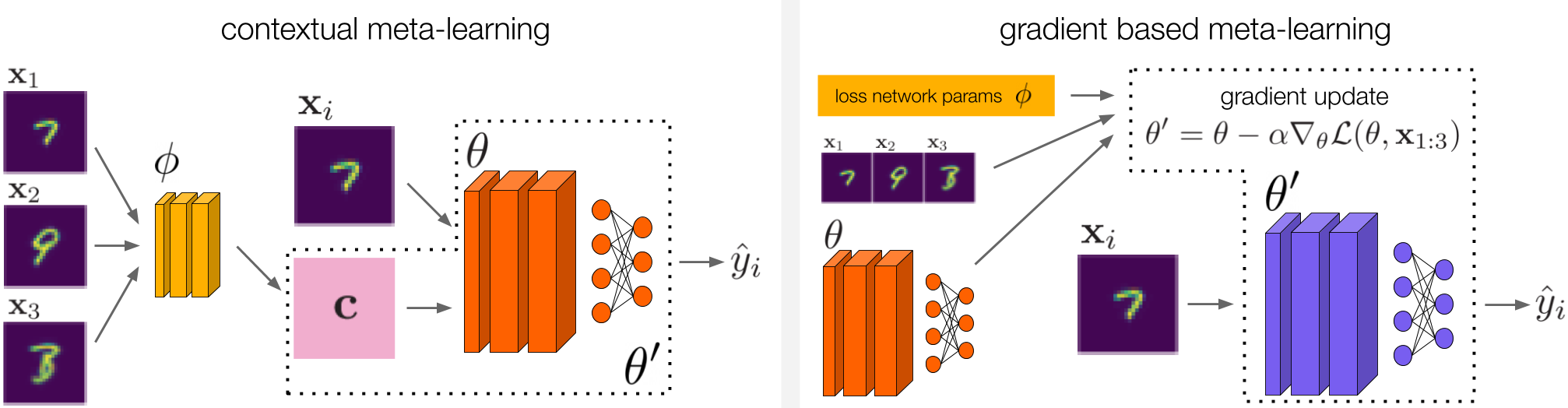
我们从上下文元学习(左)和基于梯度的元学习(右)中汲取灵感,以便为ARM设计方法。对于上下文元学习,我们研究了属于此类别的两种不同方法。这些方法在我们的论文中有详细描述。
与元学习的联系是ARM框架的主要优势之一,因为在设计解决ARM的方法时我们并非从头开始。特别是在我们的工作中,我们从上下文元学习和基于梯度的元学习中汲取了灵感,以开发出三种解决ARM的方法,我们将其命名为ARM-CML,ARM-BN和ARM-LL。我们在这里省略了这些方法的详细信息,但是它们在上图中进行了说明,并在本文中进行了全面描述。
我们构建的方法的多样性证明了ARM问题表述的多功能性和普遍性。但是我们实际上使用这些方法观察到了经验收益吗?接下来我们调查这个问题。
实验
在我们的实验中,我们首先对四种显示组分布偏移的不同图像分类基准进行了与各种基准,先前方法和消融相比的ARM方法的全面研究。我们的文章提供了基准和比较的完整详细信息。
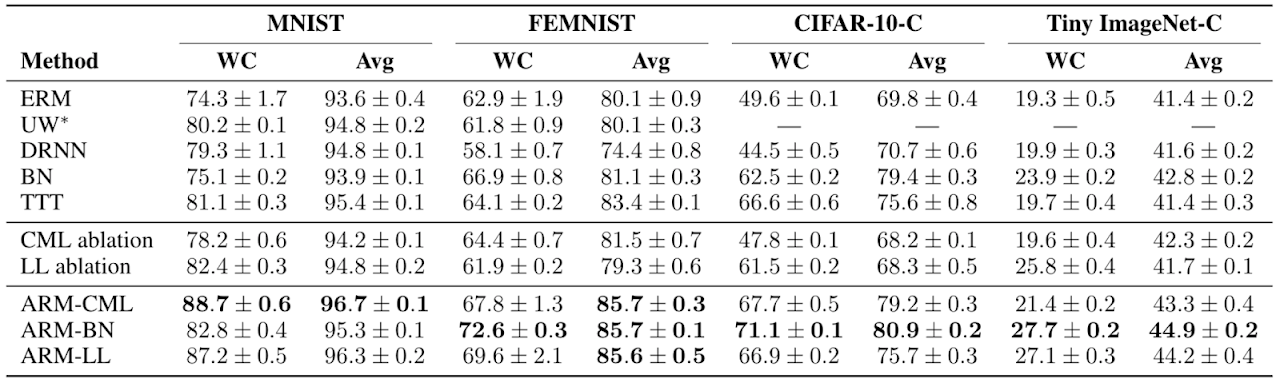
我们发现,与以前的方法相比,ARM方法凭经验得出的结果是,各组的最坏情况(WC)和平均(Avg)性能都更好,表明最终训练模型的鲁棒性和性能都更好。
在我们的主要研究中,我们发现,与许多先前的方法以及其他基准和消减方法相比,ARM方法在最坏情况和各组的平均测试性能方面总体上表现更好。ARM-BN的最简单方法(只需几行附加代码即可实现)通常效果最佳。这从经验上显示了元学习的好处,因为可以对模型进行元训练以充分利用自适应程序。

我们还进行了一些定性分析,其中我们调查了与开头描述的激励示例相似的测试情况,该用户编写了双层a。我们凭经验发现,在给定足够多的用户手写示例(包括其他“ a”和“ 2”)的情况下,使用ARM方法训练的模型实际上确实可以成功地适应和预测“ a”。因此,这证实了我们最初的假设:训练自适应模型是应对分布偏移的有效方法。
我们认为,从一开始的激励实例和本文的实证结果就令人信服地主张进一步研究自适应模型的通用技术。我们提出了对这些模型进行元训练以更好地利用它们的适应能力的通用方案,但是仍然存在许多悬而未决的问题,例如自己设计更好的适应程序。这一广泛的研究方向对于机器学习模型在复杂的实际环境中真正实现其潜力至关重要。
作者介绍
